
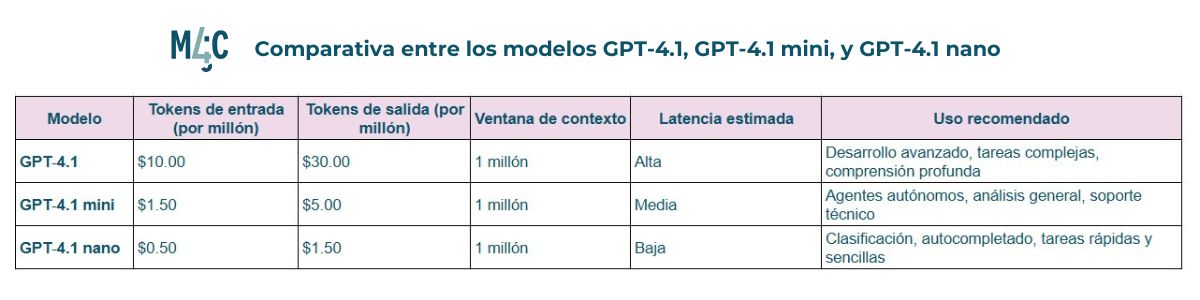
OpenAI He launched three new models of artificial intelligence: GPT-4.1, GPT-4.1 Mini and GPT -4.1 Nano. These improved versions exceed their predecessors to generate codefollow -up instructions and comprehension of long contexts, also offering a Greater efficiency and reduced costs. With a context window expanded to 1 million tokens and an updated knowledge base until June 2024, these models are available exclusively through the company's API.
The main model, GPT -4.1, stands out for its performance in coding tasks, exceeding GPT -4O in 21% and 27% to GPT -4.5 in standard evaluations. Mini and Nano versions offer cheaper and faster solutions, maintaining a high level of performance, which makes them ideal for a wide range of applications, from autonomous agents to analysis of large volumes of data.
Next, we analyze the performance of the three models in different areas, with real examples.
Code generation performance: improved precision and efficiency
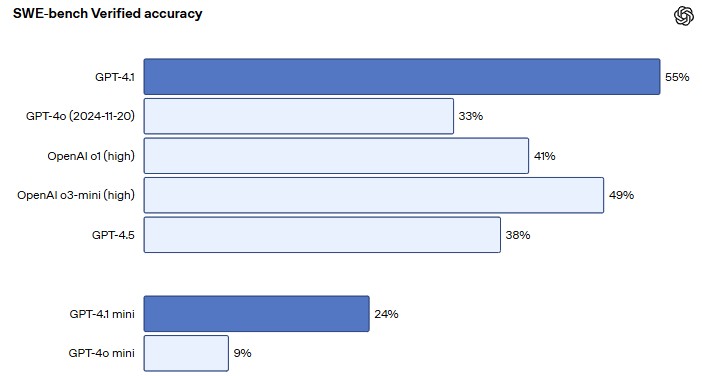
GPT -4.1 has been specifically optimized for overcome real challenges in software engineering. In the Swe-Bench Verified evaluation (metric that evaluates the ability to solve tasks based on incident descriptions in code repositories, generating functional and validated patches), this model reached 54.6% effectiveness, compared to 33.2% of GPT -4O, which represents an absolute improvement of 21.4%.
Among the outstanding improvements, GPT -4.1 demonstrates greater consistency when using toolsbetter firing of DIFF formats, and a remarkable Reduction in unnecessary editions. These skills do more reliable For tasks such as Frontend coding, agents -based development and large file refactorization (a common software development practice to reorganize and optimize the code within extensive files without changing its external functionality).
GPT-4.1 Minidespite its reduced size, equals or exceeds GPT -4o in intelligence evaluationsreducing latency almost halfway and cost by 83%.
Finally, GPT -4.1 Nano, the fastest and most economical model, achieved a 9.8% score in the Aider Polyglot Coding test (a benchmark designed to evaluate the capacity of the LLMs in the edition and generation of code in multiple programming languages), surpassing GPT -4o Mini, which is impressive considering its size and speed. In addition, it obtained a score of 80.1% in MMLU (it measures the understanding of multitasking language and knowledge) and 50.3% in GPQA (it measures the capacity of deep reasoning in physics), which makes it an ideal option for tasks such as classification and self -fulfilled.
These improvements allow developers create more efficient applications, From coding assistants to automatic code review systems, facilitating artificial intelligence integration into software development processes.
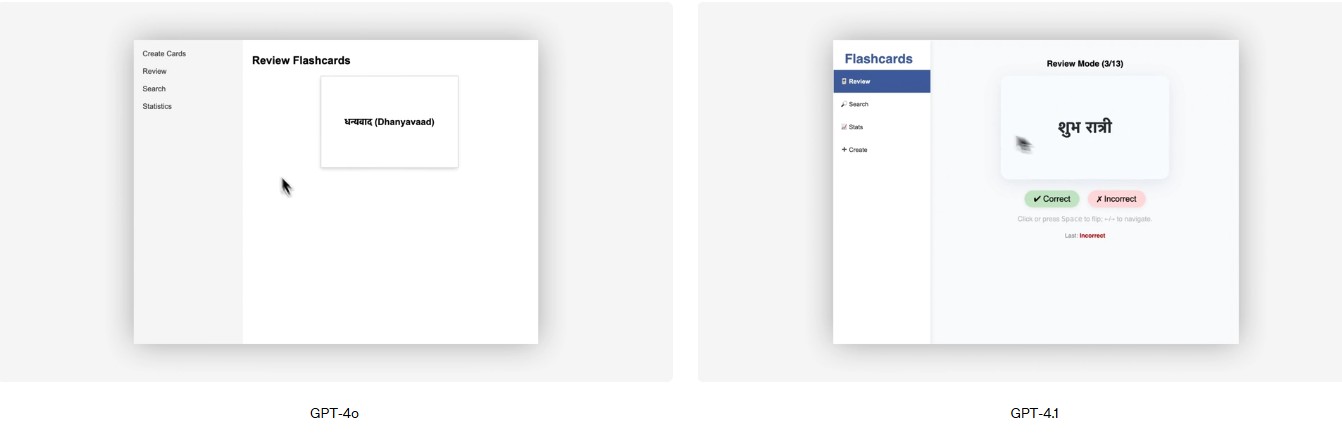
For example, during a demonstration, GPT -4.1 was able to develop an application of educational cards (known as Flashcards) for language learning, following detailed instructions and adapting to the specific needs of the user.
More reliability and understanding of instruction monitoring
GPT –4.1 significantly improves its ability to follow instructions, exceeding previous versions such as GPT -4O, especially in complex tasks. This improvement has been measured by an internal evaluation developed by OpenAI, focused on 6 areas:
Personalized format: It generates answers in structures such as XML, Yaml or Markdown.
Negative instructions: Avoid explicitly prohibited behaviors.
Sequential orders: Respect the exact sequence of steps indicated.
Content requirements: ensures the inclusion of mandatory information.
Classification: Organize data according to specific criteria (as a population).
Uncertainty Management: Respond with “I don't know” or channel the consultation if there is no data.
Each category is evaluated in difficulty levels: easy, medium and difficult. GPT -4.1 stands out especially at difficult levels, with 49% precision compared to 29% of GPT -4O.

In it Benchmark Scale's Multichallenge (Evaluation developed by Scale AI to measure the ability to maintain realistic and complex conversations with multiple interaction shifts), GPT -4.1 obtained 38.3%, a 10.5% jump compared to GPT -4O. This improvement translates into more natural interactions, reducing the need to reformulate indications.
This is especially useful for building autonomous agents that interact with users or systems, such as virtual assistants, incident resolution systems, or creative writing agents.
For example, companies such as Blue J and What (Specialized in code generation) have implemented GPT -4.1 to generate precision legal documents and academic summaries, while the editing tool Windsurf and the agency Thomson Reuters They use it in development environments where each instruction must be followed to the letter.
Deep understanding of long contexts
All models of the GPT -4.1 family support a 1 million tokens context windowallowing to process extremely long text files. In the video-MME evaluation, GPT-4.1 reached 72% in the “Long, Non-subtitles” category (length, without subtitles), an improvement of 6.7% compared to GPT -4O.
This allows new use cases such as analysis complete of Technical documentationthe Reading financial reports of hundreds of pages, or the Understanding video or subtitled scripts With a single consultation, identifying key trends and providing understandable analysis for strategic decision making.
In addition, thanks to this capacity, it is possible Build agents operating autonomously for hoursmaintaining coherence and precision without the need to restart the context.
Image generation
Although GPT -4.1 models are not multimodals as gpt –4o, have been designed to integrate effectively With image generation toolsimproving coherence between text and image. This allows developers to create applications that combine detailed textual descriptions with precise visual representations, facilitating the creation of attractive and personalized multimedia content.
For example, an application can use GPT -4.1 to generate detailed descriptions of products and then, through a image generation tool, create visual representations that coincide with those descriptions, improving the user experience and the efficacy of marketing.
Photo: Openia




